「AI技術を生かすためのスキル」を咀嚼する
この記事の趣旨
AI技術を生かすためのスキルを読みました。データ分析をビジネスの意思決定にどうつなげられるか?という点について、納得・共感できる点がよくまとめられている本です。ただ、構成や数式が若干わかりにくかったので、自分なりに咀嚼して残しておこうと思います。咀嚼したため、元の本の意図とは離れている部分もあります。気になる方は是非当書をお買い求めください。
KPI-アクション-モデル-最適化-フレームワーク
ビジネスの課題をデータ分析で解くために必要な要素があります。大きく分けてKPI-アクション-モデル-最適化の4つの部分に分かれます。 以下の模式図でフレームワークを示します。
KPI
特に当書で特別な意味はなく、一般的な定義で良いです。これを最大化するために意思決定を行います。
アクション
アクションとは、意思決定によって何かを制御することを指します。例えば、コンビニの来店客数を増やしたいという目的がある場合には、「店員の人数」・「入荷する商品の配分」・「営業時間」はすべて意思決定により制御できるはず*1ですので、それらを制御することはアクションです。対して、「店の前の人通りの人数」・「近くに住んでいる人数」は意思決定により制御できるとは考えられないので、これらを制御することはアクションとは呼ばないこととします。
KPIを最大化するようなアクションを知ることが目的です。
モデル
モデルとは、アクションがKPIにどのような影響を及ぼすか表現するものです。モデルは、ある1つの「真のモデル」が存在するわけではないので、捉え方によって様々なモデルが存在します。例えば、「店内のお菓子の種類が多いと来店客数も多い」「店内のお菓子の種類をとすると来店客数
は
となる」「店内のお菓子の種類を
とすると来店客数
は平均
、分散
の正規分布に従う」はそれぞれモデルです。しかし、次の重要な考慮点があります。
因果と相関
因果関係を知りたいというのが当然の欲求です。しかし、ありもののデータで集計してわかるのは相関までであり、それは因果とは異なります。因果を得るためにはA/Bテストを行ったり、ありもののデータに対してどうしても因果が知りたいのであれば、かなり気を付けながら因果推論用の分析をする必要があります。因果と相関を意識しながら書くと文章が長くなってしまうので、この記事では相関を因果とみなして記述します。ご容赦ください。因果推論に関してはこちらのプログやこちらの教科書やこちらの動画がおすすめです。Couseraの講座もわかりやすかったのでぜひ受講してみてください!
最適化
最適化とは、制約の下でKPIを最大化するようにアクションを決めることです。例えば、「店内のお菓子の種類が多いと来店客数も多い」というモデルが与えられたなら、アクションの「入荷する商品の配分」をすべてお菓子に割り振るべきでしょう。しかし、「ある程度はお弁当をそろえる必要がある」などの制約があるでしょうから、これらの制約を満たしつつできるだけお菓子の入荷種類を増やすことが現実的なシナリオでしょう。
具体例
離反予防
あるサービスの離反が多いことがビジネス上の問題であるとします。それを分析で何とかしたいとしましょう。
KPI
離反率をKPIとするのが直感的ですが、そうすると利益につながらないような顧客のみを引き留めてしまう可能性があります。よって、顧客全体のCLV合計からアクションにかかる費用を引いたものをKPIとします。
は
番目の顧客のCLV、
は
番目の顧客にかけるアクションのコストです。
回収できるくらい価値のある顧客にはコストをかけて離反防止をしますが、回収できそうにない顧客は離反することを許容します。
アクション
解約を抑止できるクーポンを顧客に配るかどうかを決められるとします。クーポンは一種類だとします。
モデル
繰り返しになりますが、モデルは現実の近似ですので、様々な考え方ができます。ここでは一例を紹介します。
ある顧客が離反するなら1、離反しないなら0となる確率変数をとします。ある顧客にクーポンを配ったら1、配らなかったら0となる確率変数を
とします。このとき、顧客が離反しないときのCLVを
とすると、
となります。それぞれの顧客ごとにクーポンを配信するときの個別KPI*2は、
に注意して、
クーポンを配信しないときの個別KPIは、
となります。
最適化
をKPIを最大化するように決定します。どのように
を決定すればいいかというと、クーポンを配信したときの個別KPIがクーポンを配信しなかったときの個別KPIを上回ればいいので、
となるようなに対して
とすれば良いです。この式から顧客ごとに次の3つを推定する必要があることがわかります*3。
- クーポンを配布したときの離反確率
- クーポンを配布しないときの離反確率
- 離反しない場合のCLV
離反確率は回帰問題として機械学習の手法を利用することが考えられます。CLVの推定はいろいろあるようです。
結言
一通りの流れを書いてみました。おそらく大体の問題はこのフレームワークで考えていけるんじゃないかと思ってます。今回は簡単な例だったので順に考えていきましたが、実際はそれぞれの要素を行きつ戻りつしながら考えていくのだと思います。特にモデルと最適化の境目は明確につけられていないと自分でも思います。
ただ、分析をする以上何かしらの目的はあるべきであると考えていて、それはKPIの向上に帰結するはずだと思っています。どのKPIを上げるか、上げるためにどんなアクションがあるか、アクションはKPIにどのような影響を及ぼすか、最適なアクションは何か、今後も考えていきたいです。
LuxAIコンペで銅メダルのためにやったこと
LuxAIで銅メダル取れました
kaggle LuxAIコンペでギリギリ銅メダルを取ることができました。116thです。

コンペの取り組み方針や実施したアプローチの詳細を書いていこうと思います。
やったこと
アプローチ三分類
ルールベース
まずはデータサイエンスを用いず、完全にルールベースで取り組みました。この段階ではルールを読み込みながらアイデアをひたすら実装する段階でした。
強化学習
強いAIを作るための花形技術といえば強化学習ですね。pythonでは以下の組み合わせで手っ取り早く実装できそうでした。
学習を実行するところまでは実現できましたが、残念ながら記録は伸びませんでした。コンペのdiscussionを見てもopengym+stable-baseline3でうまくいっている人はいないようでした。コンペの1stは強化学習でしたが、使っているアルゴリズムは異なるようでした。今後深掘りしたいです。
教師あり学習
今回のコンペでは投稿されたAIの対戦履歴が得られる仕様でした。よって、上位者の行動を正解として分類問題に落とすことができました。今回のコンペではモデリングの自由度が高いことが面白い点でした。例えば、各wokerごとに予測を出すのか、全てのマスに対して同時に予測を出すのかなどで説明・目的変数・モデルアーキテクチャが様々考えられます。教師あり最も強かったアプローチは、ゲームのマップの情報を階層構造として説明変数とし、全てのマスについてworkerの行動を予測する方針で、モデルとしてはUnetを使うものでした。Unetはセグメンテーションでよく用いられるもので、各ピクセルに対してクラスを予測するものですからうまくフィットしたと考えています。
終わりに
強化学習でうまくいかなかったのが心残りなので上位の解法を再現して深掘りしたいです。
その予測、必要ですか?~意思決定分析と予測の活用を読んで~
この記事は?
企業のDXを支援するコンサル会社に勤めてきた中で、予測モデルを作る経験をしてきました。二値分類モデルならconfusion matrixをもとにモデルを評価するのが一般的でしょうが、結局、案件の状況で正解率や適合率などに見る指標を変えてるなあと思っていました。ある時、この本に出会い、「モデルの価値は意思決定問題によって変わる」ということが明確に理解できました。意思決定支援のためにデータ分析する人は全員読んだ読んだほうがいい本です。個人的にとても感動したので、共有するために書きます。
二値分類モデルの良さってconfusion matrixなの?
一般的に二値分類モデルの性能はconfusion matrixで評価することが推奨されています。しかし、これには問題があると筆者は考えます。
- confusion matrixは予測の確からしさを測ると解釈できますが、そもそも予測を得ること自体に価値はない。予測を得ることで意思決定が向上することで初めて価値が生まれると考えます。天気予報を見て傘を持っていくかどうかをの判断することができれば、天気予報に意味はありますが、折り畳み傘をいつも持ち歩くと決めているなら天気予報に意味はないですよね。
- 意思決定をどれくらい良くするかがconfution matrixのみでは決まらない。例を挙げます。まったく同じconfusion matrixを持つ二値分類モデルがあります。ただし、虚報は少ないようですが、見逃しが多いようです。つまり、適合率は高いですが、再現率が低いようです*1。次の二つの意思決定問題を考えてみます。
①工場の検査工程の不良品検査を二値分類モデルで代替し、省人化したい。不良品を出荷してしまうと顧客の信頼を完全に失うことになる。
➁工場の検査工程の不良品検査を二値分類モデルで代替し、省人化したい。不良品を出荷したとしても、顧客はその前提で商品を購入している。
前者では見逃しが許されず、後者では見逃しはある程度許容できそうです。よって、省人化のメリットが同量だとして、➁ではそのメリットが十分なら受け入れられそうですが、①の案件では受け入れられないでしょう。同じconfusion matrixを持つモデルでも意思決定問題によってその価値が変わることがわかります。
つまり、予測の価値は意思決定問題と分離して考えることはできないです。よって、意思決定の営み自体をモデル化し、その中で予測が生む価値を考えていきます。
意思決定のモデル化
意思決定本を参考にして、次のような意思決定の問題を考えてみます。
あなたはある工場のマネージャーです。工場では月の終わりに、来月稼働する生産機械の数を調整することができます。稼働する生産機械が多ければたくさん製品が作れますが、すべて売れるとは限りません。製品の需要は景気によって左右されることがわかっています。利益を最大化するために、来月何台稼働させれば良いかというのが問題です。
問題の構成要素
天下り的ですが、意思決定モデルの構成要素を紹介します。
行動
これはどの選択肢を選ぶかということを意味します。例えば、傘を持っていくかどうかという意思決定問題の行動は、「傘をもっていく」と「傘をもっていかない」の2つです。
自然の状態
行動の価値は、自然の状態によって変化します。例えば、自然の状態が「雨」「晴れ」の二種類あったときに、「傘をもっていく」という行動の価値は異なります。また、それぞれの自然の状態の確率も考えることができるでしょう。
利得
ある自然の状態における行動の価値です。例えば、自然の状態が「雨」「晴れ」、行動が「傘をもっていく」「傘をもっていかない」の時に、利得の行列は、
| 傘をもっていく | 傘をもっていかない | |
|---|---|---|
| 雨 | 濡れなくてうれしい! | 濡れて辛い |
| 晴れ | 無駄な荷物だった | 手ぶらで楽 |
というように表せます。
今回の問題において
さて、今回の意思決定問題におけるこれらの要素を明確にしていきましょう。
行動は、稼働台数が自然数ならば何でも良さそうですが、簡単のため、「1台稼働させる」「2台稼働させる」にします。それぞれ
,
と表します。
自然の状態は景気について考えることにします。簡単のため、「好景気である」「不景気である」にします。それぞれ
,
と表します。また、過去のデータの調査から
,
ということがわかっています。これは、現場の主観的な確率ということにします*2。
利得行列を考えましょう。今回は、好景気では2台稼働させるとたくさん作れてたくさん売れてめっちゃ儲かりますが、不景気に2台稼働させると製品が売れず余ってしまうので、稼働費用の分だけマイナスになるとします。1台稼働させる場合は、量は作れないので儲けはそこそこですが、不景気でも売り切れるとします。これを数値化して利得行列を表します*3。
| 2台稼働させる |
1台稼働させる |
|
|---|---|---|
| 好景気 |
700 | 300 |
| 不景気 |
-300 | 300 |
そもそも、予測する価値はあるのか?どれくらい予測することにコストをかけるのか?
「来月の景気が予測できれば、最適な稼働台数が決められるのになあ」とだれかが言いました。「そうだ!AIに予測させよう!」 ということで来月の景気をAIに予測させて、それをもとに稼働台数を決めるプロジェクトが走ることになりました。
まあ、やりたいことはわかります。でも少し落ち着いてください。現時点でも、現場の感覚として来月の景気は多少予測できます。現時点での意思決定の良さを確認しましょう。また、最強のAIが出来たとしたら、来月の景気は必ず当てることはできますが、そのときの意思決定は現在と比べてどれくらい良くなるでしょうか。それがわかれば、このプロジェクトにどれだけ予算をかけていいかざっくりわかるはずです。
決定木分析
まずは、今回の意思決定問題がどんなものかわかりやすくするために可視化してみましょう。決定木という手法を用いると、今回の意思決定問題は次の図のように表せます。
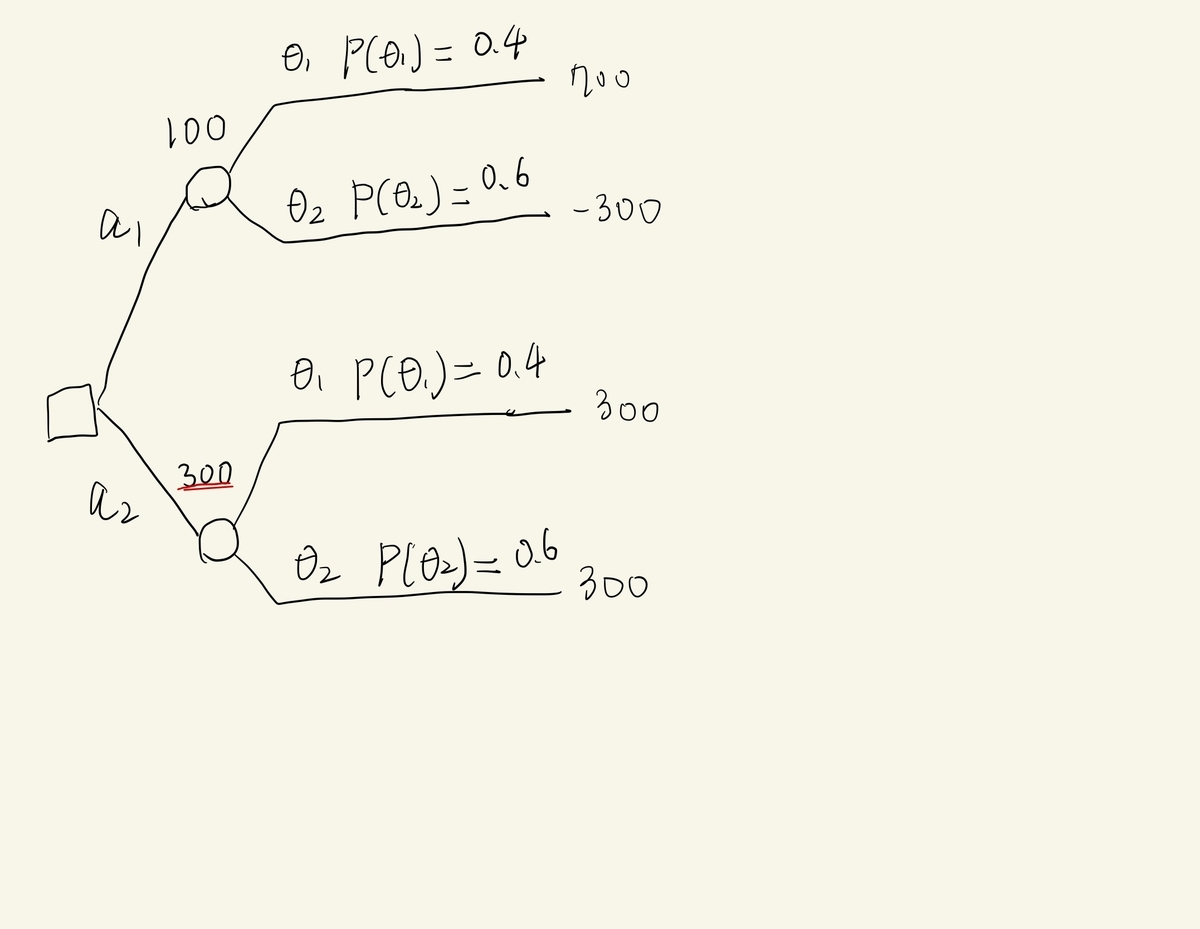
を選ぶことはどのくらい良いでしょうか。それは、
を選んだときの、利得の期待値で表すことが素直でしょう。これを
(Expected Monetary Value)とよび、
が与えられたとき
をした時の
を
と表します。各決定ノードの上にこれを書いてあります。今回の意思決定問題のときでは、
となります。
予測なしで意思決定
予測なしの意思決定の価値は、予測なしでを最大化するように意思決定したときの
でしょう。よって、予測なしの意思決定の価値
は、
となります。
完全情報による意思決定
完全情報とは、今回の意思決定問題では、来月の景気を絶対に当てることができるということです。なら
を選び、
なら
を選ぶので、そのときの意思決定の価値
は、
予測AIプロジェクトの実施可否への考察
上記の計算から、予測によって生み出すことのできる価値の最大量は、
となります。よって、このプロジェクトで得られる価値は最大でも180万円ですから、それがまず目安となるでしょう。
意思決定モデルの下での二値分類モデルの価値
ここからは、予測が得られるとして考えていきます。
予測がある場合の 問題の構成要素
予測がない場合の構成要素に加えて、以下の要素を考えます。
予測
行動をとる前に得られるとします。今回の場合は、「来月が好景気である」、「来月が不景気である
」のどちらかであるとします。
ある二値分類モデルの価値
まずは、二値分類モデルの性能を与えます。confusion matrixが次であったとしましょう。
| 好景気予測 |
不景気予測 |
|
|---|---|---|
| 好景気 |
|
|
| 不景気 |
|
|
好景気をpositiveと考えて、正解率85%、再現率は87.5%、適合率は77.8%のモデルです。このモデルの予測が与えられたときの意思決定問題を考えてみます。これも決定木で表してみます。
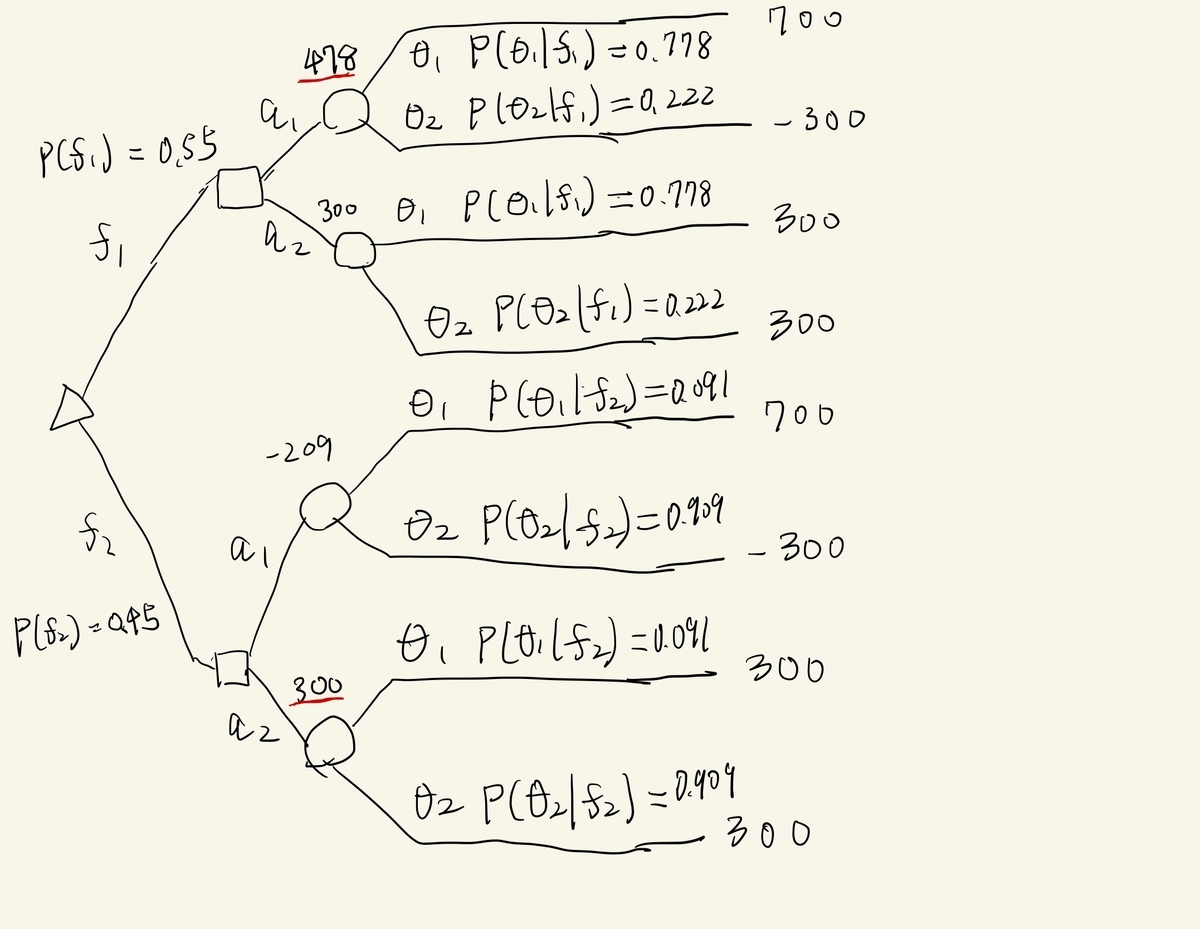
の下で、行動
を取るときの期待利得は、
となります。ですから、の時は
、
の時は
を選ぶので、予測があるときの意思決定の価値
は、
となります。この結果からこの予測モデルは80万円の価値があったことがわかりました*5。
まとめ
ここまで読んでいただいた方は、まずは参考にした意思決定分析と予測の活用を読んでください。
自然の状態が2つの意思決定問題について二値予測モデルの価値を測ることができました。今後さらに勉強していきたい内容を述べます。何か知っている方がいたら教えてください。
モデルの拡張。単純にマルチクラスにするとどうなるのでしょう。線形回帰して顧客をスコアリングし、それをもとに意思決定する場合はどのように考えればいいのでしょう。
因果推論との関連性。因果性をもとに意思決定する場合も現実世界ではあると思うのですが、その場合も今回と同じように考えてもいいのですかね?つまり、
を投薬の有無にして、
ベイズ統計との関連性。
ってベイズ統計でいう主観確率っぽい印象を受けるのですが、よくわかりません!ここは全く分からないときは一様分布にしてしまっていいのでしょうか。
Signateコンペでみる時系列データの定常性の影響~intro~
この記事は?
Signateコンペ日本取引所グループ ファンダメンタルズ分析チャレンジを題材に、時系列データの取り扱いで勉強したことを共有する記事です。時系列データの取り扱いの注意点と、対処法を理論と実践で紹介していきたいです。
コンペ内容
詳細はコンペページを見てもらうとして、概要を説明すると、
- 各銘柄について、明日から20日間の最高値、最低値への変化率(それぞれlabel_high, label_lowと呼ぶことにします)を予測する。ただし、予測対象となる日は決算短信が発表された日のみである。
というコンペです。予測対象となる日は限られていますが、目的変数は時系列データとして解釈できます。例えば、トヨタのlabel_highは
 となります。
となります。
時系列データって何を気を付けなければいけないの?
時系列データの前に、非時系列データの機械学習について考えていきます。例えば、アヤメの例を考えていきます。ここで、どのアヤメに所属するかを表す目的変数を、アヤメの特徴量を
とします。機械学習する目的は
が与えられたときに、どのような
の確率分布になるか、つまり、
を精度よく推定できるモデルを作ることです。
 時系列データに話を戻します。時系列データとは何でしょうか。一般的には、時々刻々と変化しうる確率分布から得られる実現値を意味します。例えば、株価データなら、時々刻々と平均が変動するような確率分布から毎日ひとつだけ実現値が得られていると考えます。*1
時系列データに話を戻します。時系列データとは何でしょうか。一般的には、時々刻々と変化しうる確率分布から得られる実現値を意味します。例えば、株価データなら、時々刻々と平均が変動するような確率分布から毎日ひとつだけ実現値が得られていると考えます。*1

、
*2のデータが与えられたときに
の確率分布を求めることです。つまり、
を精度よく推定するモデルを得ることです。
目的は明確になったので、どうやるか考えていきます。例えば、100時点分のデータがある場合、非時系列データが100個ある時と同様に考えてモデルを作ってしまっていいのでしょうか。いや、そうではないですね。非時系列データは100個のデータからある一つの確率分布を推定しますが、時系列データでは、各時点で異なる確率分布ですからこのように考えることができません。言い換えると、時系列データが100時点あるというのは、ある一つの確率分布から100個データが得られたわけではなく、100個の確率分布から1個ずつ得られているだけです。
どうすればいいでしょうか。例えば、時系列データを次の図のように変換できないでしょうか。

このように確率分布が時々刻々と変化しない性質を定常性、そうでない性質を非定常性と呼びます*3。続きの記事では、非定常の時系列データを定常な時系列データに変換する方法の理論、そして実際にやってみてどのようにモデルの性能に影響を及ぼすか書いていきたいと思います。
MMM(マーケティングミックスモデル)をRobynでやってみた
この記事は?
マーケティングミックスモデル(MMM)を、facebookが開発しているRライブラリ(Robyn)でやってみた記事です。
MMMとは?
MMMを何のために使うか?
広告を出している企業にとって、チャネルごとの適切なコスト配分は最も気にするポイントですよね。であれば、過去の実績からその問いに答えられるのではないでしょうか。
MMMは何を行うのか
一般的には、売上データと各種チャネルの投資額、その他売り上げに影響を及ぼすさまざまな要因の時系列データの間の関係を仮定し、その仮定のもとで売り上げを各チャネルの貢献量に分解するアルゴリズムです。
たとえば、ある企業が、Web広告、交通広告、TV広告を出していて、売り上げにそれぞれどれだけ貢献しているかを把握したがっているとします。これらのデータだけでも売り上げへの貢献量を各チャネルに分解できるでしょう。
 しかし、この企業がアイスクリーム屋だとすると、夏場に売り上げが上がることになりますが、このままだとこの売り上げの向上量も各広告の効果であると解釈されてしまいます。であれば、気温データを追加して、この気温による効果による売り上げ貢献もあると仮定することが良いでしょう。
しかし、この企業がアイスクリーム屋だとすると、夏場に売り上げが上がることになりますが、このままだとこの売り上げの向上量も各広告の効果であると解釈されてしまいます。であれば、気温データを追加して、この気温による効果による売り上げ貢献もあると仮定することが良いでしょう。
 このように様々な時系列データを追加して、売り上げを様々な効果に分解していくことがMMMの行っていることです。*1
このように様々な時系列データを追加して、売り上げを様々な効果に分解していくことがMMMの行っていることです。*1
RobynでMMMやってみた
チュートリアルでの問題設定
Robynのチュートリアルでは、次の仮定を置いて問いに答えようとしています。
 例えば、Facebookへの投資額は、インプレッション数に影響を与え、インプレッション数がさらに売り上げへ影響を及ぼすと考えます。このように、広告の投資額から売り上げへ直接の効果を考えるのではなく、中間の指標を用いることによってモデルの精度が上がる場合があります。
例えば、Facebookへの投資額は、インプレッション数に影響を与え、インプレッション数がさらに売り上げへ影響を及ぼすと考えます。このように、広告の投資額から売り上げへ直接の効果を考えるのではなく、中間の指標を用いることによってモデルの精度が上がる場合があります。
実際に分析していくデータは次のようなものです。


| カラム名 | 説明 |
|---|---|
| DATE | 日付 |
| revenue | 売り上げ |
| tv_S | TV広告への投資量 |
| ooh_S | OOH広告への投資量 |
| print_S | 印刷媒体広告への投資量 |
| search_S | 検索エンジン広告への投資量 |
| facebook_S | Facebook広告への投資量 |
| search_clicks_P | 検索エンジンでの広告のクリック数 |
| facebook_I | Facebook広告のインプレッション数 |
| competitor_sales_B | ある同分野競合他社の売り上げ |
ほとんど上記で置いた仮定と対応したカラムです。competitor_sales_Bは業界全体に影響を及ぼす効果をこれで測定できるとします。
プログラムの実行
ここはRobynのドキュメントに従って実行しただけです。
アウトプットの解釈
Robynは様々なプロットを出してくれます。これらを見ていけば売り上げの各要因の寄与と、モデルの妥当を確かめていくことができます。
問いに答えるためのアウトプット(クライアントに見せる系)
各要因の売り上げへの寄与割合
全期間で平均したときの各要因の売り上げへの寄与割合です。
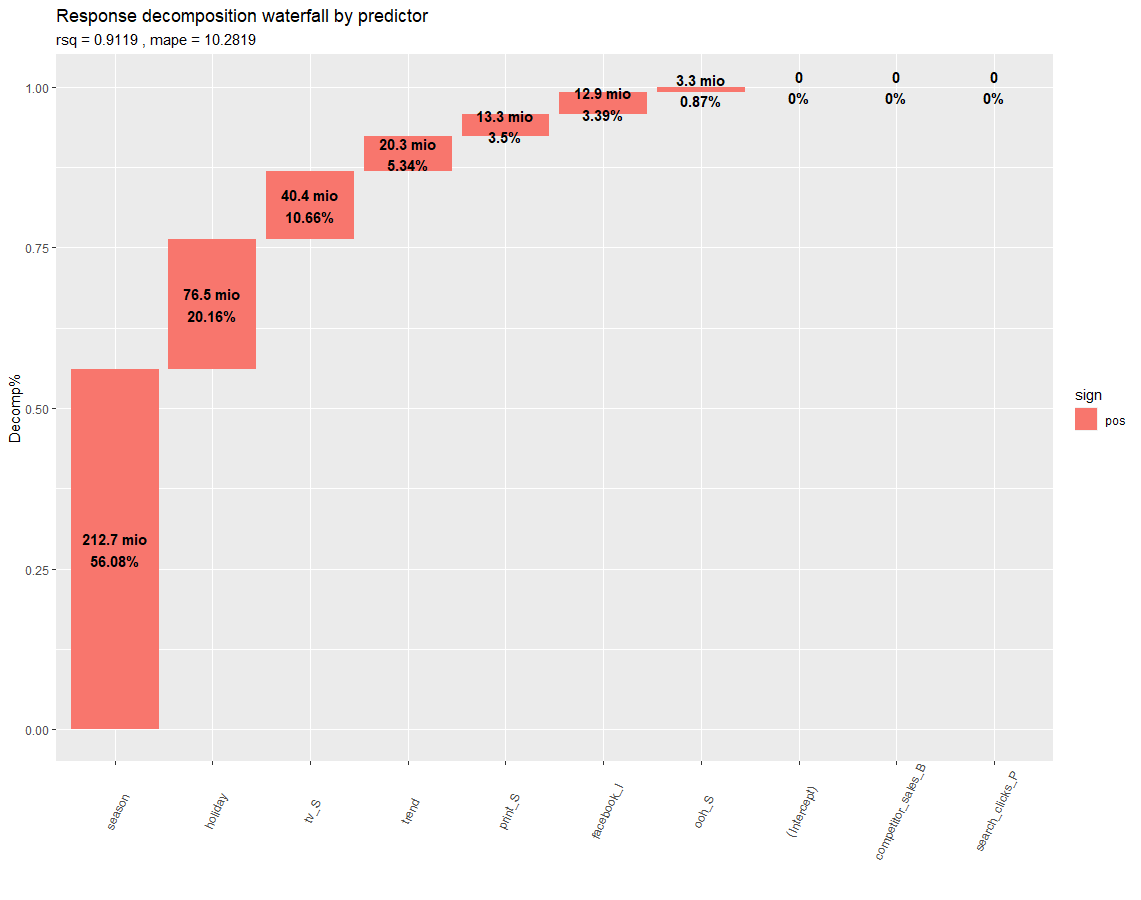 図からわかることは、
図からわかることは、
- 広告全体による売り上げの寄与割合は約20%でした。つまり、広告を出さなかったらおそらく売り上げは8割になります。
- 検索エンジンの寄与は0%でした。このチャネルには投資しなくてよさそうです。
などがわかります。
時系列での各要因の売り上げへの寄与量
時系列で各要因の売り上げへの寄与量を確かめてみます。
 時系列でみて特徴的な部分がわかります。
時系列でみて特徴的な部分がわかります。
- 12,1月が売上のピークで、4,5月が谷のようです。(なんの企業なんでしょうね?)
- ときどき絶大な効果を持つ休日があります。なぜ売り上げが上がっているかを深堀すれば、広告の施策に生かせるかもしれません。
各チャネルのROI
各チャネルの効率性を表す図です。全期間での投資量の合計に対して、売り上げへの寄与量が上回っていれば1より大きくなります。

- 印刷媒体は投資量は最も少なかったですが、効率性は最も高いです。ここには投資額を増やしてもよさそうですね。
- 逆にOOH広告、Facebook広告、検索エンジン広告は効率性が1より小さいので投資額を減らすべきでしょう。
ここでの注意点は、この図だけでは最適な投資配分が決められないということです。広告の投資額とリターンの関係は、diminidhing returnであると仮定されることが一般的です。つまり、投資額が小さいうちは効率が良く、投資額が大きくなると効率が悪くなります。
 よって、最適な投資配分を求めるためには、このグラフを各チャネルに対してプロットする必要があります。
よって、最適な投資配分を求めるためには、このグラフを各チャネルに対してプロットする必要があります。
各チャネルの反応曲線
各チャネルの反応曲線をプロットしました。*2

 列が各チャネル、上段のピンク色の線が反応曲線、上段の青線が利益、下段がROIです。よって、最適な投資額は青線が最も上に来たときの横軸となります。印刷媒体は21290であると読み取れますね。(他はプロットの仕方が悪く、つぶれてしまってよくわかりません。。。)
列が各チャネル、上段のピンク色の線が反応曲線、上段の青線が利益、下段がROIです。よって、最適な投資額は青線が最も上に来たときの横軸となります。印刷媒体は21290であると読み取れますね。(他はプロットの仕方が悪く、つぶれてしまってよくわかりません。。。)
反応曲線を描ければ、残りの2つも描けます。投資額がであるときの利益は、反応曲線を0から
まで積分した値から
を引けば求められます。また、ROIは反応曲線の微分です。
最適コスト配分
最適な投資配分です。注意点としては検索エンジンチャンネルは効果0なのでうまく計算できず、それを取り除いた前提でのプロットです。
 上でROIを確認し、TVとFacebookチャネルは効率が低く、ほかの2つが高いことがわかっていたので、それと整合している結果になっています。トータルのコストを変えることなく、1.3%の売上額向上が見込めそうです。
上でROIを確認し、TVとFacebookチャネルは効率が低く、ほかの2つが高いことがわかっていたので、それと整合している結果になっています。トータルのコストを変えることなく、1.3%の売上額向上が見込めそうです。
分析の妥当性を確かめるためのアウトプット(分析者が裏で確かめておく系)
売り上げデータの当てはまり
一般的な時系列モデルの性能の確かめ方は、ある時点までのデータからモデリングして、その時点以降のデータにどれだけ当てはまっているかで評価します。まずはモデルが出力する売り上げデータと実績を比べてみましょう。
 テストデータに対するMAPEは約10%でした。売り上げが数千万単位の10%なので、十分な性能といえるでしょう。
テストデータに対するMAPEは約10%でした。売り上げが数千万単位の10%なので、十分な性能といえるでしょう。
残差プロット
予測と実績の差を残差といいます。この残差を3つの観点でプロットしてくれます。
 残差分析では、さらにモデルの性能を上げるためのアイデアが得られることがあります。例えば、今回は観測値が極端な部分で予測精度が悪くなる傾向がみられます。これを予測できるような要因を思いつけば、それを観測してモデルに組み込むことによりモデルの性能が上がることがあります。
残差分析では、さらにモデルの性能を上げるためのアイデアが得られることがあります。例えば、今回は観測値が極端な部分で予測精度が悪くなる傾向がみられます。これを予測できるような要因を思いつけば、それを観測してモデルに組み込むことによりモデルの性能が上がることがあります。
感想とまとめ
Robynを使用すれば、各種時系列データをインプットすることにより、MMMに必要なアウトプットが一通り得られました。
便利だと思う一方、まだドキュメントが充実してなかったり、プロットがすごくみにくいのが難点かなと思いました。中身のアルゴリズムに関してはこれから勉強して聞こうと思います。
Machine Learning Design Patternsの要約と実務経験からの感想
この記事は?
Machine Learning Design Patternsを読んで内容を要約しました。そのあと、実務でデータサイエンスをしている経験から何か面白いことを書こうと思います。
Machine Learning Design Patternsの概要
章立てとしては、全八章あり、第一章で概要、第二章~第七章で用途別のデザインパターンの紹介、第八章でMLOps総論を述べています。著者のおすすめする読み方は、頭から全部読むのではなく、先に第一、八章を読んでから興味のある章を深読みしてほしいとのことでした。ですので、先に第八章から読んでいきます。
Capter8
MLプロジェクトのパターン
MLのライフサイクル
MLのライフサイクルをDiscovery, Development, Deploymentに分けて考える。
Discovery
ビジネスユースケースの定義、データ探索のステップに当たる。
ビジネスユースケースの定義
- 立場によって成功の定義が異なるので、評価指標を明確にすることが大事。(Chapter1)
- ビジネスインパクトを考えるには、従来のシステムをベンチマークにすべき。(Chapter7)
データ探索
- データ品質が十分かどうか確かめるため、さまざま図を描き、統計量を確認する。
Development
データ探索、アルゴリズム選択、データパイプライン特徴量エンジニアリング、MLモデル作成、評価、結果プレゼンのステップに対応する。
アルゴリズム選択
- MLモデルへの問題の落としこみ方のデザインパターンはChapter3にある。
データパイプライン特徴量エンジニアリング
- 特徴量エンジニアリングパイプラインが必要であり、データ表現のデザインパターンはChapter2に詳細がある。
- パイプラインで保証するMLシステムの再現性とレジリエンスはCapter5とChapter6にある。
モデル作成
- MLワークフローのベストプラクティスに従うべし。(Chapter6)
- 典型的なモデルトレーニングのループはCapter4で解説されている。
- モデルの開発は反復的なものである。このときの再現性を確保するデザインパターンはChapter6にある。
結果のプレゼン
- Chapter7に、AIが責任をもって使われるためのデザインパターンがある。
Deployment
デプロイ計画、モデルを運用可能にする、モデルをモニターするステップを含む。
デプロイ計画
- MLモデルを運用化するときに直面する問題のためのデザインパターンはChapter5で触れられている。
モデルを運用可能にする(MLOps)
- ワークフロー実行を自動化する。例えば、Kubeflowなどは、UberのMichelangeloやGoogleのTFXで使われている。
- CI/CDの恩恵はMLモデルにもある。例えば、モデルが更新されるたびに、データクリーニング、バージョニング、データパイプラインのオーケストレーションが行われる。
モデルのモニター
- モデルは様々な要因で劣化する。継続的なモデルの性能のモニターが必要だが、Chapter5で詳しく議論されている。
AIへの準備レベル
Googleのホワイトペーパーによると、企業のAIへの準備レベルは3段階に分かれる。戦術的、戦略的、適応的である。
戦術的フェイズ:手動デプロイ
- ビジネスゴールが明確でないPoC段階によく見られる。
- データは手動でアクセスされ、自動化されたML開発サイクルもない。
- MLOpsはモデルリポジトリに制限され、テストと商用環境の差はほとんどない。
戦略的フェイズ:パイプラインの活用
- ビジネス目標と優先度に沿っており、シニアエグゼクティブの助力がある。
- 開発環境と商用環境の明確な違いがある。
- モデル開発はきちんと管理された実験であり、組織内で共有されている。
- データパイプラインはスケジュールに基づいて自動実行される。
適応的フェイズ:完全自動化処理
- AIはイノベーションを促進し、アジリティを支援し、実験と学習の文化を培う。
- Chapter5とChpter6の再現性とレジリエンスのデザインパターンが関連する。
- プロダクトごとにAIチームが存在し、横断的な先進分析チームから支援される。
- データセットはすべてのチームからアクセスでき、再利用できる。
- MLパイプラインは自動化され、組織の誰でもアクセスできる。
感想
以下は個人の感想です。不確実な情報が含まれています。鵜呑みにしないでください。
弊社のAIへの準備レベル
弊社の情報
- コンサル会社で、クライアントから依頼を受けてデータ分析をします。ので、プロダクトとかはないです。
- 分析案件の大部分は、基礎分析して示唆を出して施策考える系の分析。この種類の案件には、定期的なモデル運用は含まれていない。
弊社のAIへの準備レベル
戦略的フェイズではあるが、大規模には活用されていない状態だと思います。
- 定期的なモデル運用を含む案件に関しては、運用までのパイプラインは整備されている。分析チームがプロトタイプ開発をした後、運用チームがAirflowで定期バッチ組むという流れです。
- 上記の通りモデル運用まで行われない案件が多数なので、大規模には活用されていない。
弊社の適応的フェイズとは
こんな風になったらいいなという感想。
- 各プロジェクトの分析内容が、社内のだれでもトレースできる。さらに、その分析に対して気軽にコミットできる。(特徴量追加してみたら性能上がったよとか、こっちのアルゴリズム使ってみたら学習時間短くなったよとか)
- プロジェクトを横断的に見て、全体の分析レベルを上げる組織がある。
- 分析チームと運用チームが分かれるのでなく、ひとつのチームで分析から運用まで全部やる。それにより、コミュニケーションコストが下がり、アジリティが上がる。そのために、全自動パイプラインにより、運用の属人化を防がなくてなならない。
むしろプロダクト開発側のチームとも一体になる。どのような分析で価値を出すかという観点も含めてプロダクトをデザインする。DataMesh構造を作る。 watanta.hatenablog.com
...とはいえ、そもそもモデル運用しない案件が今は多数なので、効果は限定的な気がする。
この本の重点的に読みたい点
- 各プロジェクトの分析内容が、社内のだれでもトレースできる。さらに、その分析に対して気軽にコミットできる。
特にこの世界実現したいですよね。各プロジェクトのモデルがKaggleコンペになるようなのができたらすごく面白そう。ビジネス得意な人はクライアントと相対して、案件全体の分析設計する人がいて、モデリングは社内に任せるみたいな。で、一番性能出せた人はボーナスもらえるんですよ。絶対面白いでしょ。
このためには、分析内容がノーコストで再現できないといけないですよね。Chapter5とChpter6に書かれてるようなので、ここから読みたいと思います。
DataMeshの論理アーキテクチャ
この記事は?
前回はDataMeshの概念についてまとめました。今回はこちらの記事でデータメッシュの論理構造が解説されているので、まとめていこうと思います。
運用データと分析データの断絶
企業でのデータは運用データと分析データに分けられる。運用データとはビジネスを運営しているときに得られるデータである。分析データは、ビジネスにおけるファクトを集約したデータで、MLモデルや分析レポートに使われる。
この2つのデータプレーンは、分断されていて、ETLパイプラインでつながれている。そして、両方が拡大しETLパイプラインが複雑になるにつれて、ジョブが定期的に失敗するようになったりしてメンテナンスが大変になることはおなじみの光景である。

 データメッシュはこの2つのデータプレーンを従来とは異なる構造で接続しようとする。2つのデータプレーンをマイクロサービスとしてその中に一緒に入れ込んでしまい、外からはAPIでアクセスする。
データメッシュはこの2つのデータプレーンを従来とは異なる構造で接続しようとする。2つのデータプレーンをマイクロサービスとしてその中に一緒に入れ込んでしまい、外からはAPIでアクセスする。
DataMeshの論理アーキテクチャと原則
データメッシュの目的は分析データを最大限活用できるスケールする基盤を作ることである。データソースと消費者(分析データを使うもの・ひと)の増加、ユーズケースの増加によるデータ変換と処理の多様化、変化への即応性などに対応する。これを達成するため次の4つの原則がある。
1.ドメイン志向のデータオーナーシップとデータアーキテクチャの分解
2.data as a product
3.self-serve data infrastructure as a platform
4.連合計算ガバナンス
ドメインオーナーシップ
データメッシュでは、責任はデータに最も近い人に分散される。スケーラビリティと継続的な変更を支援するためである。どのようにするかが問題である。
今日の組織はドメインごとに分割されているが、データメッシュもそれに沿う。これにより、システムの変更の影響を局所的にできる。
この例では、架空のメディアストリーミング会社(spotifyとか)を例にする。この会社も運用で分割されていて、”ポッドキャスト”チームはポッドキャストの運用と配信のシステムを運用しており、”アーティスト”チームはアーティストへの支払いシステムを運用している。データメッシュはこれらドメインごとが分析データを提供することに責任を持つ。例えば、”ポッドキャスト”チームはもちろん運用のためのAPIに責任を持つが、それだけでなく、分析用のデータのAPIにも責任を持つ。
論理アーキテクチャ:ドメイン指向データ
このアーキテクチャは分析データの提供とデータの処理コードのリリースをドメインごとに独立させる。スケールするため、このアーキテクチャはドメインチームが運用データAPIや分析データAPIをデプロイすることに関して、自立性を支援する。
角度名員は一つ以上の運用APIと分析APIを持つ。
 また、ほかのドメインのAPIにあるドメインが依存していることもある。例えば、”ポッドキャスト”ドメインは”ユーザ”ドメインの"ユーザーアップデート"分析APIを、ポッドキャストのリスナーとユーザデモグラフィックを結合するため、利用していることもあるだろう。
また、ほかのドメインのAPIにあるドメインが依存していることもある。例えば、”ポッドキャスト”ドメインは”ユーザ”ドメインの"ユーザーアップデート"分析APIを、ポッドキャストのリスナーとユーザデモグラフィックを結合するため、利用していることもあるだろう。

Data as a product
現在の分析データアーキテクチャでは、次のことに多大なコストがかかる。データ見つけること、データを理解すること、データ信頼すること、データの品質を担保することである。データメッシュにおいて、ドメインが増加するにつれてこれらの問題は悪化する。ここでData as a product(製品としてのデータ)の原則が必要となる。データを製品として扱い、消費者を顧客とみなすことにより、これらの問題に対処する。
製品としてのデータが満たす性質はこちらの記事に述べられている。製品してのデータを扱うチームは、ドメインデータプロダクトオーナーを設けるべきである。この役職は、データが製品としてデリバリされることを保証するための測定に責任がある。この測定はデータ品質、データを使い始められるまでのリードタイム、データの消費者の満足度などを含む。ドメインデータプロダクトオーナーは、だれがそのデータを分析するのか、どのように使うのかに深い理解を持たなければならない。また、データのユーザとデータプロダクトオーナーが会話することにより、データプロダクトのインターフェースを構築していく。
各ドメインはデータプロダクトデベロッパーを含み、その人はそのドメインデータを開発し、メンテナンスし、提供することに責任を持つ。データプロダクトデベロッパーは運用を担当するエンジニアと一緒に仕事をする。これにより、従来と比較して、データのオーナーシップが上流へと移動する。
論理アーキテクチャ:データプロダクトはアーキテチュラルクオンタムである
ドメインが自律的に製品としてのデータを提供し消費することを支援するため、データメッシュはデータプロダクトをアーキテクチュラルクオンタムとみなす。アーキテクチュラルクオンタムは、独立に変更可能なシステムの最小単位である。
データプロダクトは、次の3つのコンポーネントを持つ。
- コード:コードは次の3つを含む。(a)データをドメイン運用システムから受けて、処理して提供するためのコード、(b)APIとして提供するためのコード、(c)アクセスコントロールポリシー、コンプライアンス、来歴を追跡するためのコード
- データとメタデータ:データは分析データと履歴データである。メタデータは計算内容、シンタックスの定義、質の指標などを含む。
- インフラストラクチャ:ストレージへのアクセス、データプロダクトのビルド、デプロイ、実行を可能にする。
 次の図はアーキテクチャクオンタムとしてのデータプロダクトを表現する。
次の図はアーキテクチャクオンタムとしてのデータプロダクトを表現する。


セルフサービスデータプラットフォーム
データプロダクトをビルドし、実行し、モニターし、アクセスするためには、かなりの量のインフラストラクチャが必要である。しかし、このインフラストラクチャをプロビジョニングするスキルは専門的で、各ドメインで複製するのは難しい。各ドメインのチームがデータプロダクトを自律的に所有するためには、データプロダクトのライフサイクルの煩雑さを取り除くインフラストラクチャが必要である。ここで新たな原則を紹介する。ドメインの自律のためのセルフサービスデータインフラストラクチャである。
このインフラストラクチャで使われる技術は、今日のサービス運用のためにのものとは異なる。例えば、ドメインチームはdockerコンテナをサービスとしてデプロイし、kuberbetsをオーケストレーションのためにプラットフォームとして使うかもしれない。しかし、データプロダクトではdatabricksクラスタでsparkジョブとしてパイプラインを実行するだろう。データメッシュではこの2つの異なるインフラストラクチャを接続する必要がある。 セルフサービスデータインフラストラクチャは、ドメインデータプロダクトデベロッパーがより少ないコストで専門性がなくてもデータプロダクトを開発・運用することを支援しなければならない。セルフサービスデータインフラストラクチャが満たすべき性質はこちらにまとめられている。
論理アーキテクチャ:マルチプレーンデータプラットフォーム
セルフサービスプラットフォームは複数のプレーンに分割される。
 セルフサービスプラットフォームは複数のプレーンを持ち、異なる機能を提供する。例えば、
セルフサービスプラットフォームは複数のプレーンを持ち、異なる機能を提供する。例えば、
- データインフラストラクチャプロビジョニングプレーン:データプロダクトのコンポーネントを実行するのに必要なインフラストラクチャのプロビジョニングを支援する。これは。分散ファイルシステム、ストレージアカウント、データプロダクト内部コードのオーケストレーション、データプロダクトのグラフ上の分散クエリエンジンのプロビジョニングなどを含む。このプレーンは、ほかのデータプラットフォームプレーンまたは高度なデータプロダクトデベロッパーのみが直接使用する。かなり低レベルのデータインフラストラクチャプレーンである。
- データプロダクトデベロッパーエクスペリエンスプレーン:これはデータプロダクトデベロッパーがメインで使うプレーンである。これは、シンプルな宣言型インターフェースをデータプロダクトのライフサイクルを管理するために使う。これはすべてのデータプロダクトとインターフェースに適用される、全社的な基準を満たすように実装する。
- データメッシュ監督プレーン:データプロダクトの接続を提供する機能をもつプレーン。例えば、特定のユースケースのためのデータプロダクトを発見することは、データプロダクトのメッシュを検索することで提供される。もしくは、さらに高い視点のインサイトを得るために複数のデータプロダクトを掛け合わせることは、メッシュ上の複数のデータプロダクトを横断してセマンティッククエリを実行することで提供される。

連合計算ガバナンス
データメッシュでは独立したチームが独立したデータプロダクトをそれぞれのライフサイクルで開発・運用する。しかし。いくつかのデータプロダクトを統合して分析する場合には、それらが結合処理などが簡単にできるよう統一されている必要がある。データメッシュは次のようなガバナンスモデルをもつ。ドメインの自己主権、全社での標準化による相互運用性、動的トポロジー、プラットフォームによる意思決定の自動実行である。これを連合計算ガバナンスとよぶ。ドメインデータプロダクトオーナーとデータプラットフォームオーナーによって、すべてのデータプロダクトに適用されるグローバルルールを決める。難しい点としては、中央化と地方分権化のバランスをとることだ。ある規則を全社に適用するのか、そのドメインだけに適用するのかは適切に考える必要がある。
論理アーキテクチャ:メッシュに埋め込まれた計算ポリシー
連合計算ガバナンスには、支援的な組織構造、インセンティブモデルが必要である。
 前述したとおり、何を全社基準として実装し、何を各ドメインに任せるかのバランスを決めるのは、アートである。例えば、データの用語の定義は全社で決めるべきだが、データの構造はドメインごとで決めるべきである。連合計算ガバナンスのインセンティブは各データプロダクトを相互運用可能にすることであり、各ドメインのインセンティブはそのドメインのデータプロダクトの消費者を増やすことである。
前述したとおり、何を全社基準として実装し、何を各ドメインに任せるかのバランスを決めるのは、アートである。例えば、データの用語の定義は全社で決めるべきだが、データの構造はドメインごとで決めるべきである。連合計算ガバナンスのインセンティブは各データプロダクトを相互運用可能にすることであり、各ドメインのインセンティブはそのドメインのデータプロダクトの消費者を増やすことである。
 これは従来の中央集権データ管理チームが、データに対してゴールデンスタンダードを決めるのとは異なる。あくまで、各ドメインの自律性を支援しつつ、それらの代表者が集まるものとして連合計算ガバナンスがある。次の図は、中央化されたデータ(データレイク、データウェアハウス)とデータメッシュでのデータガバナンスの違いである。
これは従来の中央集権データ管理チームが、データに対してゴールデンスタンダードを決めるのとは異なる。あくまで、各ドメインの自律性を支援しつつ、それらの代表者が集まるものとして連合計算ガバナンスがある。次の図は、中央化されたデータ(データレイク、データウェアハウス)とデータメッシュでのデータガバナンスの違いである。
| 中央化されたデータのガバナンス観点 | データメッシュガバナンス観点 |
|---|---|
| 中央化したチーム | 連合したチーム |
| データの質に責任を持つ | データの質を定義することに責任を持つ(質自体は各ドメインの責任) |
| データセキュリティに責任を持つ | データセキュリティの観点を定義することに責任を持つ |
| 規律を順守する責任がある | 規律がをどう守るかを定義することに責任を持つ |
| データの一元管理 | 各ドメインの連合によりデータを管理する |
| 多義語の正規化を行う | 複数のドメインにわたる多義語の定義をする |
| ドメインから独立している | 各ドメインの代表者で構成される |
| 明確に定義されたデータの静的構造を目指す | メッシュが動的にトポロジーを変えることにより効率的な運用を可能にすることを目指す |
| モノシリックなデータレイクやデータウェアハウスといった技術 | 各ドメインで使用されるセルフサービスプラットフォームの技術 |
| どれだけ多くのデータを管理できたかが成功指標 | メッシュのネットワークが効率的かが成功指標 |
| 人手で介入 | プラットフォームに自動処理を埋め込む |
| エラーを防ぐ | エラーを検知しプラットフォームの自動処理で回復する |
まとめ
